import time
import pandas as pd
import os
import pymysql
from selenium import webdriver
from bs4 import BeautifulSoup as bs
import requests
driver = webdriver.Chrome("C:\crawling\chromedriver.exe")
driver.get('https://cafe.naver.com/ArticleList.nhn?search.clubid=10050146')
base_url = 'https://cafe.naver.com/ArticleList.nhn?search.clubid=10050146'
cnt = 0
page = 0
conn = pymysql.connect(host='localhost', user = 'root', password = '1234', db = 'test', charset= 'utf8')
curs = conn.cursor(pymysql.cursors.DictCursor)
job_seq = 0
driver.get(base_url+'&search.menuid=122&userDisplay=50&search.boardtype=&search.totalCount=151&search.page=1')
driver.switch_to.frame('cafe_main')
response = requests.get(base_url)
html = response.text
soup = bs(html, 'html.parser')
title = driver.find_elements_by_css_selector(//*[@id="main-area"]/div[4]/table/tbody/tr[1]/td[2]/div/table/tbody/tr/td/a)
print(title)
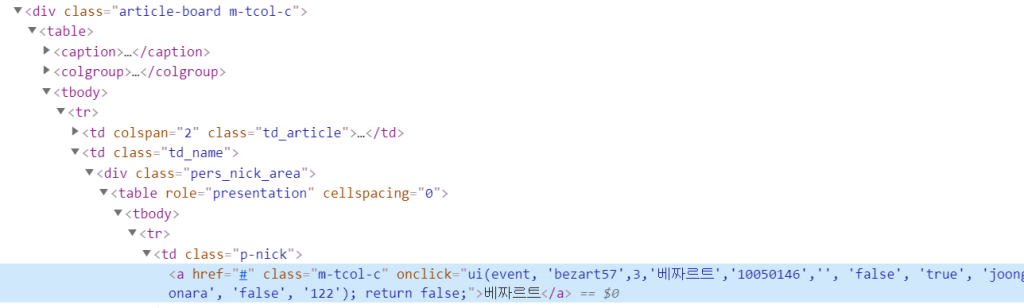
드래그 부분을 프린트 하고싶은데 . 결과값이 none 이라고 나오네요.. 어디가 잘못된걸까요?