첫번째 열과 반복해서 같은 문자인지 비교하고 같은 것의 개수를 세고 싶습니다.(채점입니다.)코랩에서 하고 있습니다.
조회수 372회
코랩에서 채점을 하고 싶습니다.
그래서 일단
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
이걸로 파일 불러오고
import pandas as pd
wordtest = pd.read_csv('/content/테스트(응답) - 11.csv')
wordtest
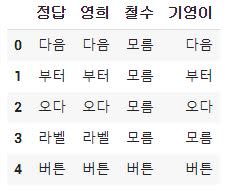
여기서 이제 비교하고 싶은데요
df = pd.DataFrame(wordtest)
columns = df.columns[1:]
new_df = df.copy(deep=True)
for i in columns:
new_df.iloc[:, i] = df.iloc[:, 0]
new_df
이건 완전히 잘못 생각하고 있는거 같습니다. 혹시 방향을 잡아 주실 수 있나요
최종적으로는 정답과 비교해서 갯수까지 세고 싶습니다.
-
-
(•́ ✖ •̀)
알 수 없는 사용자 - 〉

2 답변
-
>>> df = pd.DataFrame({"정답":["다음", "부터", "오다", "라벨", "버튼"], "영희":["다음", "부터", "오다", "라벨", "버튼"], "철수":["모름", "모름", "모름", "모름", "모름"], "기영":["다음", "부터", "오다", "모름", "버튼"]}) >>> df["정답"] == df["기영"] 0 True 1 True 2 True 3 False 4 True dtype: bool >>> len(df["정답"] == df["기영"]) 5 >>> (df["정답"] == df["기영"]).sum() 4 >>> -
scala, spark 으로 해보기
val datas = Map( "정답" -> List("다음", "부터", "오다", "라벨", "버튼"), "영희" -> List("다음", "부터", "오다", "라벨", "버튼"), "철수" -> List("모름", "모름", "모름", "모름", "모름"), "기영" -> List("다음", "부터", "오다", "모름", "버튼") ) val (keys, values) = (datas.keys.toList, datas.values.toList) val df = (values(0), values(1), values(2), values(3))._1.zip(t._2) .zip(t._3) .zip(t._4) .map { case (((a, b), c), d) => (a, b, c, d) }.toDF(keys:_*) df.agg( count(when($"정답" === $"영희", true)).as("영희점수"), count(when($"정답" === $"철수", true)).as("철수점수"), count(when($"정답" === $"기영", true)).as("기영점수") ).show +--------+--------+--------+ |영희점수|철수점수|기영점수| +--------+--------+--------+ | 5| 0| 4| +--------+--------+--------+


댓글 입력