루비에서 크롤링할 때 자바스크립트로 인해 데이터를 못 얻어오는 경우는 어떡해야 하나요?
조회수 2572회
nokogiri를 이용하여 웹크롤링을 연습하고 있는데요.
http://media.daum.net/digital/mobile/#page=1&type=tit_cont
이 url에서 아래와 같이 빨간색 친 부분의 기사의 url를 출력하는 코드를 만들어봤습니다.

하지만 해당 부분은 자바스크립트로 만들어지는 부분이라 페이지소스보기 하면 보이지않습니다. 그래서 nokogiri를 통하여 원하는 결과값이 나오지 않습니다.
크롬 개발자도구를 통하여는 아래와 같이 코드가 보입니다.

제가 짠 코드는 아래와 같습니다.
url = "http://media.daum.net/digital/mobile/#page=1&type=tit_cont"
page1 = Nokogiri::HTML(open(url))
cl =page1.css("#listWrap")
child1=cl.children
child1.each do |c|
if c.name == "li"
html_a= c.css('a').attr("href")
strH = html_a.to_s
puts strH
end
end
자바스크립트로 인하여 크롤링이 안되는 부분을 어떻게 해야 크롤링 할 수 있나요? 궁금합니다.
-
(•́ ✖ •̀)
알 수 없는 사용자
1 답변
-
open-uri대신 phantomjs, selenium, watir를 이용하시면 됩니다. open-uri 는 url 데이터 그대로 획득하는 용도라 브라우저에서 동적으로 만들어내는 컨텐츠를 읽어오지 못합니다.
Capybara와 Poltergeist(phantomjs)로 다음과 같은 방식으로 구현할 수 있습니다.
visit url within ("div#listWrap") do all("li").map do |base| img_url = base.find("img")["src"] title = base.find("a.tit").text content = base.find("a.txt").text [img_url, title, content] end endfind 예외처리를 추가하고, 코드를 간추리면 다음과 같이 됩니다.
require 'capybara' require 'capybara/dsl' require 'capybara/poltergeist' include Capybara::DSL Capybara.default_driver = :poltergeist visit("http://media.daum.net/digital/mobile/#page=1&type=tit_cont") type_daum_news1 = ->b { ([b.find("img")["src"] rescue "no_img"), b.find("a.tit").text, b.find("a.txt").text] } contents = within ("div#listWrap") { all('li').map(&type_daum_news1) } p contents #=> [[img, title, contents], ... [..,contents] ]결과
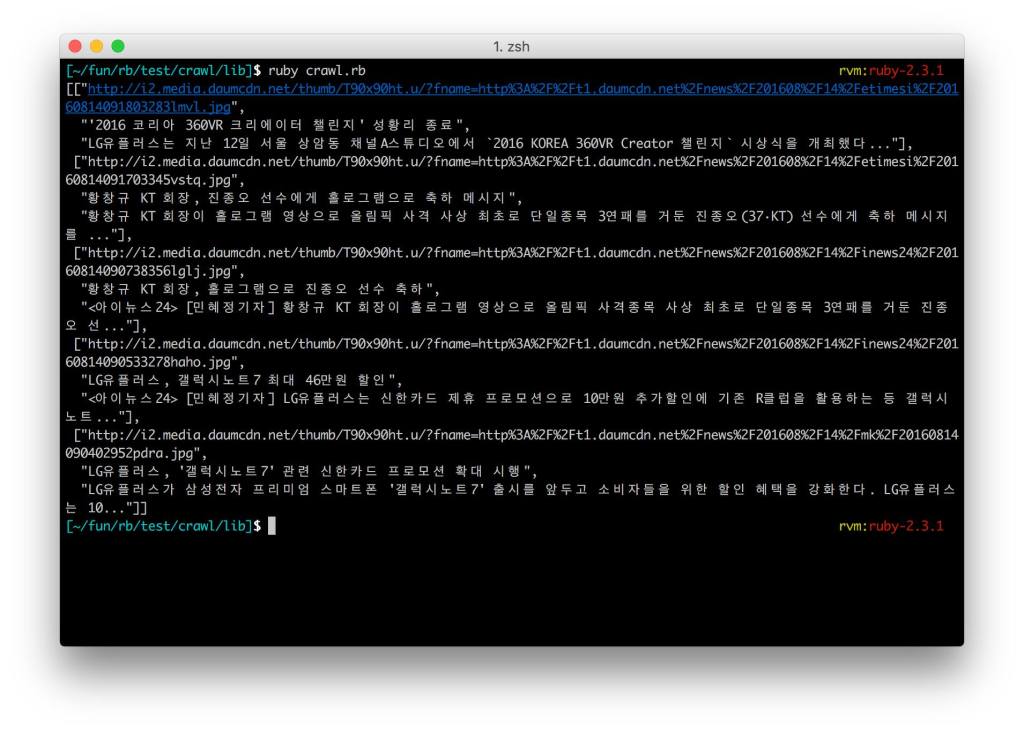
-
(•́ ✖ •̀)
알 수 없는 사용자
-
댓글 입력