(초보) 웹 크로링이 되는것도 안되는것도 있어요 ㅠ
조회수 892회
동일한 홈페이지(예 : 두인경매)에서 "경매", "공매" 카테고리로 들어가서 웹크로링를 공부중에 있습니다. 3행은 경매, 4행은 공매인데, 경매(3행 url_) 실행하면 (8행) tots 값이 나오는데, 공매(4행 url_) 실행하면 tots값이 안 나옵니다.(3행과 4행중 하나씩만 수행) ㅠ
두개의 HTML을 분석해서 'div.page'가 각각 유일합니다.
최종적으로 html 코드에 있는 (네모형태) 값을 구하려고 합니다. (경매에서 14032, 공매에서 2153) 문자열 중간에 값을 추출하는것도 쉽지 않네요. 이렇게 질문해도 되는지 모르겠네요.. 몇시간째 해보고 있는데 모르겠어요.
import urllib.request<a>
from bs4 import BeautifulSoup
url = 'http://www.dooinauction.com/auction/ca_list.php' #경매분야<a>
url = 'http://www.dooinauction.com/pubauct/list.php' #공매분야<a>
req = urllib.request.Request(url)
html = urllib.request.urlopen(req).read()
soup = BeautifulSoup(html, 'html.parser')
tots = soup.select('div.pagn')
print('Test end')
경매페이지 html 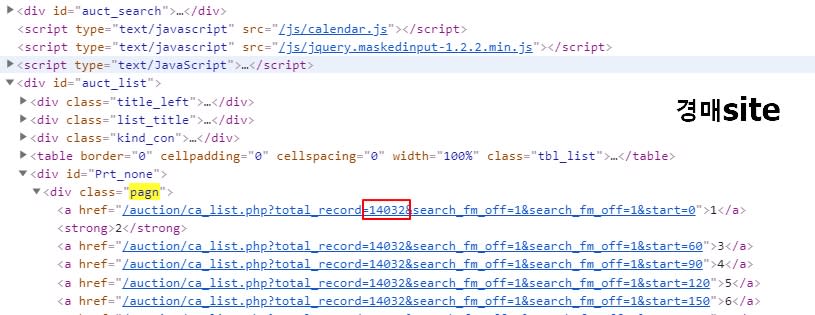
공매페이지 html 
-
-
(•́ ✖ •̀)
알 수 없는 사용자 - 〉

2 답변
-
안된다고 하는 것은 동적으로 데이터를 받아와서 클라이언트측에서 수행하기 때문입니다.
import re import requests from bs4 import BeautifulSoup url = 'http://www.dooinauction.com/auction/ca_list.php' #경매분야 html = requests.get(url).content soup = BeautifulSoup(html, 'html.parser') tots = soup.select('div.pagn a') results = [re.findall(r'total_record=([0-9]+)', link['href'])[0] for link in tots] print(results) ['14568', '14568', '14568', '14568', '14568', '14568', '14568', '14568', '14568', '14568', '14568']문제는 공매인데...아래의 링크를 이용해야 합니다 xml을 얻을 수 있으므로 파싱하여 사용하면 됩니다.
import re import requests from bs4 import BeautifulSoup url = 'http://www.dooinauction.com/xml/pubauct_list.php?pdNo=&pdStatus=1&sdate=&edate=&g_sprice=0&g_eprice=0&ctgr1=0&ctgr2=0&l_sprice=0&l_eprice=0&sido=0&gugun=0&dong=0&ref_page=&ref_sido=&ref_gugun=&ref_dong=&decrease=0&order_type=0&list_scale=20&page_scale=10&start=0&total_record=0' #공매분야 html = requests.get(url).content soup = BeautifulSoup(html, 'lxml-xml') print(soup.find('total_record').text) 2153- 넘 감사합니다. 제가 워낙 초보라서 아직 정확하게 이해하지 못했지만, 답변 주신 내용을 토대로 추가로 공부해서 수행하겠습니다. 정말 감사합니다~~ 알 수 없는 사용자 2019.12.28 23:02
- 공부중인데요... 공매에서 주신 링크는? 어떻게 이해해야 하는지요? 1페이지 뿐만 아니라 2, 3, 4 페이지 해서 마지막까지 크롤링 하려고 하는데.. 링크에 어떤 부분을 바꿔야 하는지 감이 안 오네요.. 링크가 만들어진 원리를 몰라서 그런것 같습니다. 넘 초보라 우문 해봅니다. ^^ 알 수 없는 사용자 2019.12.28 23:34
- 테스트해보니 list_scale=20 이 페이지당 항목갯수이고 start=0 이 시작하는 번호입니다. 즉 start=0 가 0이고 list_scale=20 이 20이니 1부터 20까지 가져오는 겁니다. 2페이지라는 건 start 가 20 이라는 것이죠. 정영훈 2019.12.29 01:41
-
1 페이지는 start 가 0
2 페이지는 start 가 20
3 페이지 start 가 40
충분히 이해하셨으리라 생각합니다.
- 3페이지 예
- 네. 저도 고민고민 해보고, 또 알려주신대로 하니 되더라구요. 덕분에 2153개 내용 크롤링 했습니다. 감사합니다. 그런데 또 우문을 드려야 될듯 합니다. ㅎㅎ. 알려주신 링크는 어떻게? 어디서? 구하신 건지요? HTML에서 찾지 못했고.. 유투브 보고 있습니다만 아직 답을 찾지 못했습니다. 여튼 알려주신 덕분에 크롤링 성공해서 정말 감사드립니다~~ 알 수 없는 사용자 2019.12.29 22:10
댓글 입력