파이썬 크롤링 질문
조회수 1256회
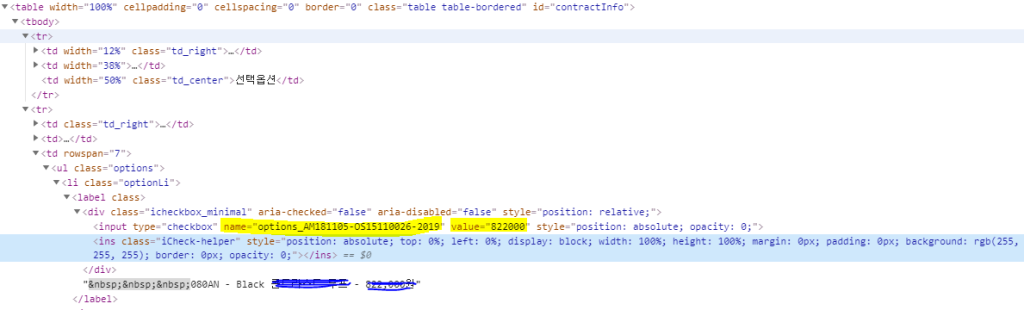
그림 노란부분을 크롤링 하고 싶습니다.
일단 HTML 까지는 파싱 했습니다만... 저 name 하고 value 가져다 출력하는 법을 모르겠습니다
import time
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from bs4 import BeautifulSoup
option_lists = driver.find_elements_by_css_selector('#contractInfo > tbody > tr:nth-child(2) > td:nth-child(3)')
driver.implicitly_wait(1)
html = driver.page_source
soup = BeautifulSoup(html,'html.parser')
-
-
(•́ ✖ •̀)
알 수 없는 사용자 - 〉

1 답변
-
그림의 노란부분을 해보기에는 주소도 모르고 html contents 도 없습니다.
비슷하게 아래 샘플을 첨부하니 참고하시기 바랍니다.
html = ''' <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ko" version="XHTML+RDFa 1.0" dir="ltr" class="js"> <body> <div id="aaaa_0"> <input type="checkbox" name="custom_name" value="11111"> <input type="checkbox" name="custom_name2" value="11111"> </div> <div id="aaaa_1">bbbb</div> <div id="bbbb_0">bbbb</div> </body> </html> ''' import re import bs4 bs = bs4.BeautifulSoup(html, 'html.parser') bs.find('input', attrs={'name':'custom_name'}) # 하나만 찾기 for tag in bs.find_all('input'): # option input 은 여러개일 수 있다. print(f"name={tag.attrs['name']} value={tag.attrs['value']}") name=custom_name value=11111 name=custom_name2 value=11111

댓글 입력