웹 크롤링하려고 하는데, 일부 항목은 클로링이 되는데, 일부 항목이 클로링이 안됩니다. 원인을 모르겠습니다.
조회수 843회
페이지내 여러요소중 크롤링 안되는 항목이 있습니다. 어떻게 해야 클로링 할수 있나요?
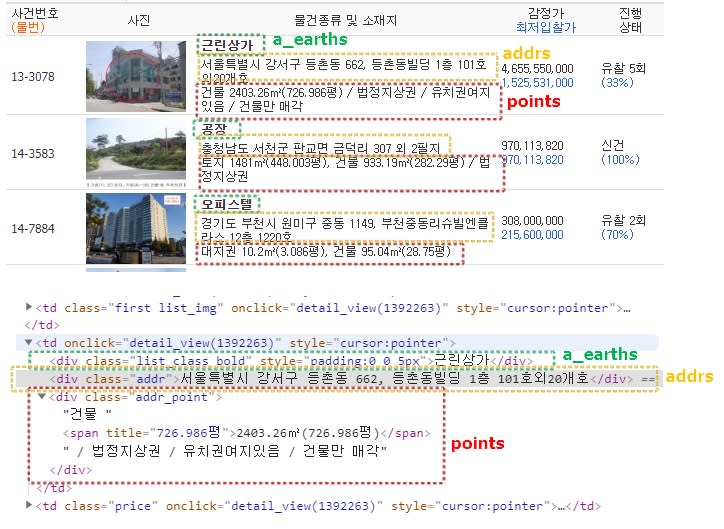
클로링 되는 항목(2개) : addrs, a_earths
클로링 안되는 항목(1개) : points
맨 마지막에 있는 "points = soup.select('.addr_point')"
이 부분이 크롤링이 안되네요. (빨간색 점선 박스내)
원인을 모르겠습니다.
자문 부탁 드립니다.
import urllib.parse
from bs4 import BeautifulSoup
import re
url = 'http://www.dooinauction.com/auction/ca_list.php'
req = urllib.request.Request(url) #
html = urllib.request.urlopen(req).read()
soup = BeautifulSoup(html, 'html.parser') #beautifulsoup 분석
tots = soup.select('div.title_left font') #총 물건수 추출등
tot = int(re.findall('\d+', tots[0].text)[0]) #
print(f'물건건수 : {tot}건')
url = f'http://www.dooinauction.com/auction/ca_list.php?total_record={tot}&search_fm_off=1&search_fm_off=1&start=0'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser') #beautifulsoup 분석
addrs = soup.select('.addr') # 클로링 OK
a_earths = soup.select('.list_class.bold') #클로링 OK
points = soup.select('.addr_point') #클로링 NO ㅠ
print()
-
-
(•́ ✖ •̀)
알 수 없는 사용자 - 〉

댓글 입력