파이썬 특정 sheet 가격 자료 resample
조회수 948회
import pandas as pd
import numpy as np
import datetime
import sys
from openpyxl import load_workbook
sys.path.append("C:\\pytest")
df= pd.read_excel('C:\\pytest\\dailyprice.xlsx', sheet_name='dprice')
No_List = ["Date", "Year", "Month"]
df.head()
df.columns
for x in range(0,len(df.columns),2):
temp_df = df[[df.columns[x], df.columns[x+1]]]
temp_df = temp_df.fillna(method='bfill').dropna()
temp_df.columns = ['Date', 'Data']
temp_df['Date'] = pd.to_datetime(temp_df['Date']).apply(lambda x: x.date())
print(temp_df)
안녕하세요.
특정 시트에 일별 가격 데이터를 수집하고 있는데 이 가격을 주별, 월별 평균 가격을 구하고 싶어서 파이썬 resample 로 변환한 후 별도 시트로 자료를 이동하려고 합니다.
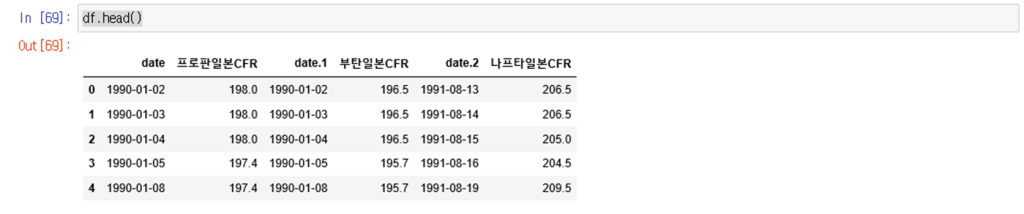
df는 위와 같은 자료로 구성되어 있으며 한 시트에 2열로 날짜와 가격 데이터가 있어 for 문을 이용하여 date와 data로 나누었습니다. 여기서 질문이 있습니다.

print(temp_df)를 하면 3가지 데이터가 표시되는데temp_df는 3번째 데이터만 표시되는 이유가 무언가요?- 저 자료를 별도 시트에 date, data 2열씩 이동하는 방법이 궁금합니다.
감사합니다.


2 답변
-
저라면, 원본 df 를 수직으로 두컬럼씩 나누어서 3개의 데이터프레임을 만든 후에 작업을 하겠습니다.
수직으로 나누는 방법은 아주 간단합니다.
iloc를 사용하면 됩니다. 아래 예제입니다.>>> df = pd.DataFrame({ "date1":[ '1990-01-02', '1990-01-03', '1990-01-04'] , "prof":[198,198, 198], "date2":[ '1990-01-02', '1990-01-03', '1990-01-04'], "buth":[196.5, 196.5, 196.5], "date3":[ '1991-01-02', '1991-01-03', '1991-01-04'], "naf":[ 206.5, 206.5, 205] }) >>> df date1 prof date2 buth date3 naf 0 1990-01-02 198 1990-01-02 196.5 1991-01-02 206.5 1 1990-01-03 198 1990-01-03 196.5 1991-01-03 206.5 2 1990-01-04 198 1990-01-04 196.5 1991-01-04 205.0 >>> df_prof = df.iloc[:,0:2] >>> df_prof date1 prof 0 1990-01-02 198 1 1990-01-03 198 2 1990-01-04 198 >>> df_buth = df.iloc[:,2:4] >>> df_buth date2 buth 0 1990-01-02 196.5 1 1990-01-03 196.5 2 1990-01-04 196.5 >>> df_naf = df.iloc[:,4:6] >>> df_naf date3 naf 0 1991-01-02 206.5 1 1991-01-03 206.5 2 1991-01-04 205.0이렇게 나누어서 프로판, 부탄, 나프타 데이터프레임을 만든 이후에 각 데이터프레임에 대해서,
- 날짜컬럼을 datetime 형으로 바꿉니다. (
pd.to_datetime) - datetime 컬럼을 인덱스로 세팅해 줍니다. (
df.set_index) - datetime 인덱스를 가진 데이터프레임이 되었으니, 원하는 시간간격으로
resample하고, resample 한 그룹에 대해mean을 구합니다. - 이렇게
resample().mean()으로 반환된 객체는pd.Series형입니다. 원한다면pd.DataFrame으로 바꾸어 주고, 디비에 저장하거나, csv 파일로 저장하던가... 합니다.
- 날짜컬럼을 datetime 형으로 바꿉니다. (
-
all_data = [] for x in range(0,len(df.columns),2): temp_df = [] temp_df = df[[df.columns[x], df.columns[x+1]]] temp_df = temp_df.fillna(method='bfill').dropna() temp_df.columns = ['Date', 'Data'] all_data.append(temp_df) print(all_data) index_data = all_data[0].set_index('Date') index_data.index = pd.to_datetime(index_data.index) df_w1 = index_data.resample('w').mean() for x in range(1,len(all_data)): index_data = all_data[x].set_index('Date') index_data.index = pd.to_datetime(index_data.index) df_w2 = index_data.resample('w').mean() df_total = pd.concat([df_w1,df_w2], axis = 1) df_w1 = df_total df_w1안녕하세요.

질문 코드를 아래와 같이 수정해서 결과값은 얻어내긴 했는데 concat 으로는 date 인덱스는 별도로 분리가 안되고 통합이 되네요..
혹시 다른 방법이 없을까요?
댓글 입력