동일한 홈페이지(예 : 두인경매)에서 "경매", "공매" 카테고리로 들어가서 웹크로링를 공부중에 있습니다. 3행은 경매, 4행은 공매인데, 경매(3행 url_) 실행하면 (8행) tots 값이 나오는데, 공매(4행 url_) 실행하면 tots값이 안 나옵니다.(3행과 4행중 하나씩만 수행) ㅠ
두개의 HTML을 분석해서 'div.page'가 각각 유일합니다.
최종적으로 html 코드에 있는 (네모형태) 값을 구하려고 합니다. (경매에서 14032, 공매에서 2153) 문자열 중간에 값을 추출하는것도 쉽지 않네요. 이렇게 질문해도 되는지 모르겠네요.. 몇시간째 해보고 있는데 모르겠어요.
import urllib.request<a>
from bs4 import BeautifulSoup
url = 'http://www.dooinauction.com/auction/ca_list.php' #경매분야<a>
url = 'http://www.dooinauction.com/pubauct/list.php' #공매분야<a>
req = urllib.request.Request(url)
html = urllib.request.urlopen(req).read()
soup = BeautifulSoup(html, 'html.parser')
tots = soup.select('div.pagn')
print('Test end')
경매페이지 html 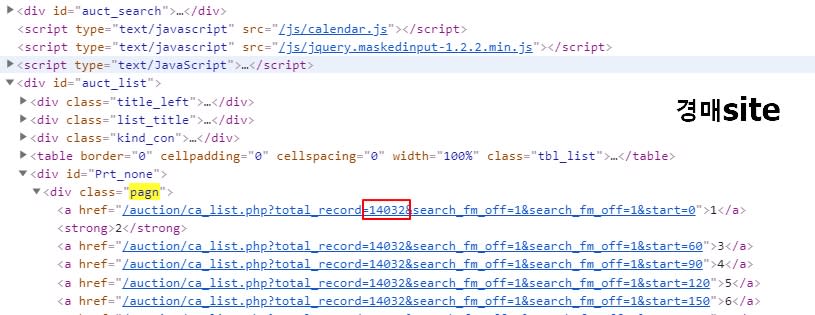
공매페이지 html 