파이썬 크롤링 질문
조회수 1433회
아프리카 비제이들이 받은 별풍선 데이터가 있는 사이트(http://poong.today/chart/day) 를
크롤링하고싶은데요 해당 사이트에서 f12를 눌러 개발자도구에서 아래사진처럼
day를 보면 순위별로 데이터가 있어서
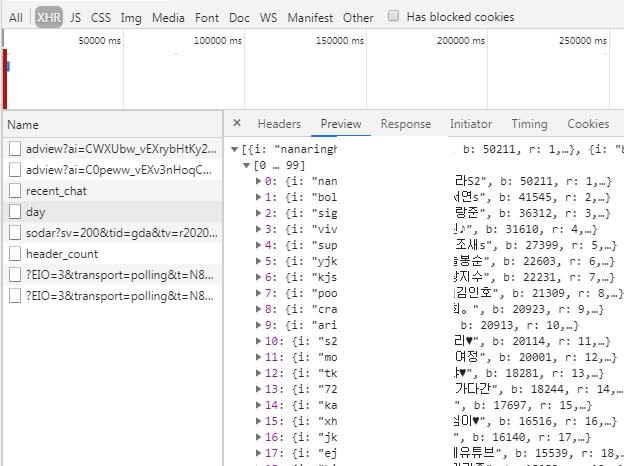
이걸 가져오고싶어서 아래처럼 코드를 post에 폼데이터를 넣어줬는데요
import requests
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}
url = 'http://poong.today/chart/day'
param = {
"year" : '2020',
"month" : '05',
"day" : '20',
"ks" : 'false'
}
req = requests.post(url,data=param,headers=header)
print(req.text)
프린트를 해보면 제가원하는 데이터가 없고 아래처럼 출력이 됩니다
<!doctype html>
<html lang="en">
<head>
<title>Page Expired</title>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Fonts -->
<link href="https://fonts.googleapis.com/css?family=Nunito" rel="stylesheet" type="text/css">
(뒷부분 길어서생략)
어디가 잘못되었는지, 제가 원하는 데이터를 request로가져오려면 어떻게 해야하는지 조언을 구합니다
아래는 폼데이터 사진입니다


1 답변
-
import requests header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'X-CSRF-TOKEN': '#일부러 가렸습니다. DEV TOOLS로 뜯어낸 값을 사용하세요', 'X-Requested-With': 'XMLHttpRequest', 'Cookie': '#일부러 가렸습니다. DEV TOOLS로 뜯어낸 값을 사용하세요' } url = 'http://poong.today/chart/day' param = { "year" : '2020', "month" : '05', "day" : '24', "ks" : 'false' } req = requests.post(url,data=param,headers=header) print(req.text)무단 크롤링을 방지하기 위해 사이트에서 이런저런 장치들을 추가한 것 같습니다.
header에 정보들을 더 추가해줘야 합니다. 구체적으로
- Content-Type 명시 (이 사이트가 아니더라도 앞으로 항상 Content-Type은 명시해주세요)
- X-CSRF-TOKEN 값 추가
- X-Requested-With 값 추가
- 쿠키 값 추가
이렇게 4개를 추가해주니 아래와 같은 Response를 얻었습니다
[{"i":"skaosdk7","n":"BJ\ud558\ub298\uc774\u2665","b":23357,"r":1,"h":[3268,3097,9989,2950,4053,"","","","","","","","","","","","","","","","","","",""],"c":208,"v":131},{"i":"gksk4998","n":"\uc140\ub9ac+\u2665","b":22718,"r":2,"h":[1374,1534,1758,5558,408,4858,7228]] ... 중략다만 여기서 X-CSRF-TOKEN값이나 Cookie값은 브라우저로 접속시 생성되는 값으로 추측되기 때문에, 주기적으로 돌아야 하는 크롤러라면 Selenium과 HeadlessChrome을 조합해서, 실제 사용자가 브라우저를 통해 접속한 것처럼 꾸미는 식으로 크롤링 해야 할 것 같습니다.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! 주의 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! 사이트 개발자가 이렇게 까지 막아 놨다면, 크롤링 등 비정상 행위로 사이트 운영에 지장을 주지 말아달라는 의미입니다. 트래픽도 결국 전부 다 사이트 관리자가 부담해야할 비용이니까요. 이런 사이트를 계속 크롤링하는게 문제가 되지 않을지는 스스로 판단하셔야 합니다.

-
(•́ ✖ •̀)
알 수 없는 사용자
댓글 입력