파이썬, 엑셀 자료 이동
조회수 1426회
시계열 통계 자료가 있습니다.
시계열 통계자료는 날짜와 데이터가 별도 열(column)로 구성되어 있습니다.

파이썬을 이용하여 구현하고자 하는 데이터 이동 방식은 위와 같습니다.
즉, 특정 월이 고정된 이후 12개를 채우는 형식입니다.
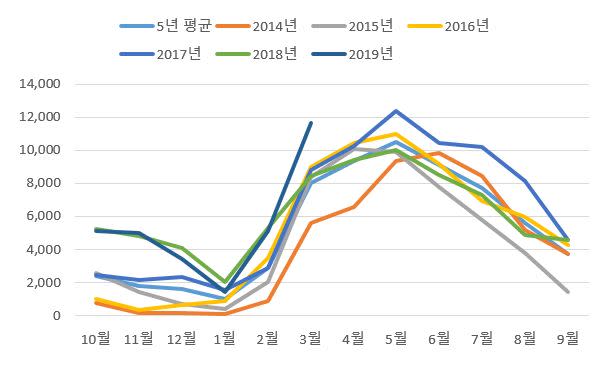
위와 같은 그래프 형태로 나타낼 목적으로 엑셀 데이터를 이동하려고 합니다.
파이썬을 통해서 엑셀 자료를 읽어온 후 간단한 데이터 이동은 가능한데 위와 같은 데이터 구성이 쉽지 않습니다.
월 고정과 5년 평균 값을 계산해야해서 일반 피벗 기능으로는 불가능할 것 같은데 좋은 방법이 있나요? 시즌 개념이라 2019년 표기된 시계열에는 2020년 자료도 포함되어 있습니다.
아무리 검색을 해봐도 잘 모르겠네요.
감사합니다.

2 답변
-
여기 제가 답변한 내용을 보시면 일별 데이터를 월별로 변환하는 pandas 코드가 있습니다. 월별로 고정할 때, year_month를 키로 해서 변환하기 때문에, 2019년 표기된 시계열에 2020년 자료가 포함되어 있다해도 문제 되진 않을 것 같습니다. 참고로 aggregation 규칙을 max로 할지 sum으로 할지 등등은 지정해주셔야 합니다
이렇게 구한 월별 DataFrame만 있으면 5년치 평균을 구하는 것이나, matplotlib로 위와 같은 그림을 그리는 건 어려워 보이지 않습니다.
원천 데이터가 어떤 모양인지 모르고, 월별로 변환할 때 어떤 규칙을 적용할 것인지 몰라서 우선 링크만 드립니다 ㅎㅎ
-
(•́ ✖ •̀)
알 수 없는 사용자
-
-
import pandas as pd import numpy as np import sys from openpyxl import load_workbook sys.path.append("C:\\pytest") df = pd.read_excel('C:\\pytest\\brazil.xlsx') # 데이터 확인 df.head() # 피벗 적용하기 위해 년월 분리 df['Month'] = df['date'].map(lambda x: x.month) df['Year'] = df['date'].map(lambda x: x.year) df1 = df.copy() df1 # 피벗 적용하여 월별로 테이블 만들기 table = df1.pivot_table(values = 'value', index = 'Year', columns='Month') table # 테이블 열 순서 변경하기 table = table[[10, 11, 12, 1, 2, 3, 4, 5, 6, 7, 8, 9]] table # 시즌별 적용을 위해 테이블 분리하기 table1 = table[[10, 11, 12]] table1 table2 = table[[1, 2, 3, 4, 5, 6, 7, 8, 9]] table2 # 테이블을 같은 연도로 붙이기 위한 작업 table2.index table2['Year1'] = table2.index - 1 table2.reset_index table2.set_index('Year1', inplace = True) table2 # 테이블 붙이기 위한 작업 table_result = pd.concat([table1, table2], axis = 1) table_result # 결측치 제거 table_result1 = table_result.copy().dropna(how = 'all') table_result1 table_result2 = table_result.copy().dropna() table_result2 # 5년 평균을 구하기 위해 5개년도만 남기고 table_result3 = table_result2.iloc[-5:] table_result3 # 5년 평균을 구해서 삽입 table_result1.loc['5average'] = table_result3.mean(axis = 0) # 결과확인 table_result1혹시 필요하신 분이 몰라 좀 무식한 방법이지만 제 나름의 해결(?) 방법을 공유합니다. 플그램에 익숙하지 않아 깔끔한 방법은 아닌 것 같지만 여튼 원하는 결과는 얻었네요..
댓글 입력