python pandas dataframe 조건에 맞게 합치고 특정 값 계산하는 방법 알려주세요.
조회수 1155회
with open("test.json", 'r', encoding="UTF8") as file:
lines = file.readlines()
json_data = [json.loads(ln.replace("\n", ""))['data'] for ln in lines]
df = pd.DataFrame(json_data)
위에서 df의 구조는 다음 사진과 같습니다.

위 형태의 dataframe에서 itemid 컬럼의 value들이 각 각 몇 개의 로우가 있는지 카운트 하기 위해
item_count = df['itemid'].value_counts(normalize=False)
해당 코드로 출력하니까 아래 사진과 같이 나왔습니다.
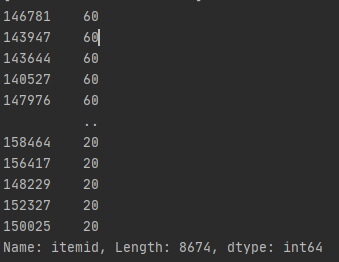
srv_id, itemid, clock, value 정보가 존재하면서 itemid들의 중복없이 value의 min, max, sum, avg(평균), num(itemid)가 반복된 회수값이 존재하는 데이터 테이블을 만들고 싶습니다.
srv_id, itemid, clock, min_value, max_value, sum_value, age_value, num
이렇게 8개의 컬럼이 존재하는 데이터 테이블을 새로 만들고 싶습니다.

1 답변
-
groupby 로 하면 될 거에요.
df.groupby('itemid')이렇게 하면 df 가
'itemid'컬럼을 기준으로 나누어져요. 그 그룹마다 각 컬럼에 대해, 어떻게 대표값을 만들 것인가가 문제이 거구요. 질문에서 명확하게 정의된 것들에 대해서만 하면 다음과 같이 할 수 있어요.df.groupby('itemid').agg( max_value=('value', 'max'), min_value=('value', 'min'), sum_value=('value', 'sum'), avg_value=('value', 'mean'))

댓글 입력