적절한(올바른) Spark 리소스 분배 또는 스케쥴링 하는 방법이 뭘까요?
조회수 435회
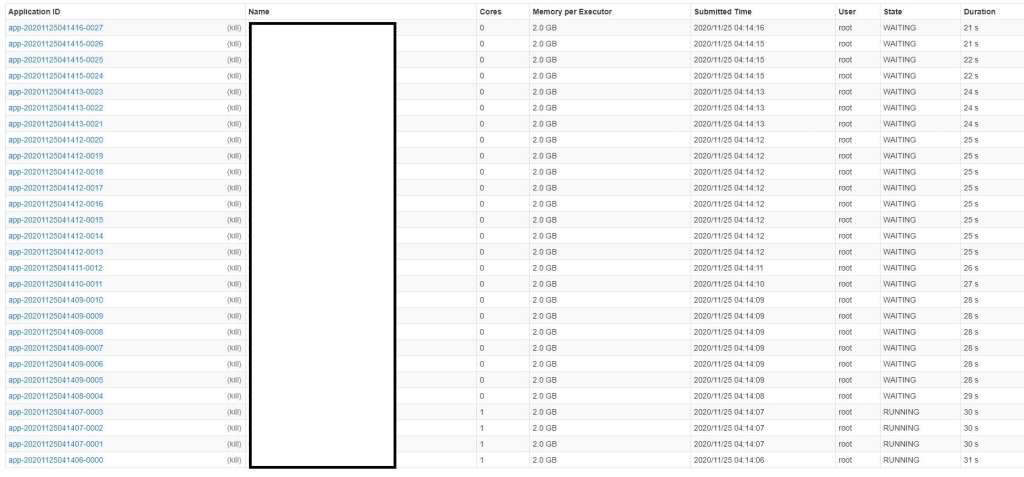
Spark를 통해 여러 python 스크립트를 병렬로 실행 하고 있습니다. 그런데 한 스크립트당 1코어씩 할당하여 동작시키다 보니까 4코어 짜리 서버에서 한 번에 수행 가능한 스크립트가 4개밖에 되질 않습니다. 좀 더 많이 병렬 처리하여 작업을 수행할 수 있을까요?
구성은 아래와 같습니다.
- 배포: standalone(서버 1대)
- worker instances : 디폴트(1개)
- 각 excutor memory : 2g
- 각 excutor core : 1개
- 한 번 실행 명령시 수행 되는 python 스크립트 개수 : 32개
- 현재 한 번에 수행 되는 스크립트 수 : 4개 (나머지 28개는 waiting상태)
- 서버 사양 : core 4개 , memory : 16g
메모리 상에서 처리해야하는 데이터 크기 자체는 크지 않습니다. 제일 커봐야 300mb 아래인데 코어수가 적다 보니까 저는 한 번에 4개씩만 돌리고 있네요... 혹시 더 좋은 리소스 분배 또는 스케쥴링 방법이 있을까요?




댓글 입력