사이트에서 파이썬으로 정보를 긁어오려는데 잘 안됩니다.
조회수 551회
http://land.seoul.go.kr/land/wskras/generalInfo.do
이 사이트구요
셀레니움으로 주소 집어넣고 나오는 토지면적 건축면적 등등의 정보를 얻고싶은데 검색해서 이것저것 해봤는데 잘 안됩니다.
검색을 해보니 ajax(?), json(?) 그런걸로 안보이는쪽에서 정보를 주고받고있는거라고해서 시키는대로 개발자도구에 네트워크에서 주고받는 json 형식으로 되어있는 제가 필요한 정보를 찾아서 referer 주소 찾고 user-agent 넣고 블로그에 올려놓은 예제 복사해다 제가 찾은 주소넣어서 해봤는데 안됩니다.
어제 저녁부터 검색해보며 이것저것 해보고있는데 잘 안풀리네요.
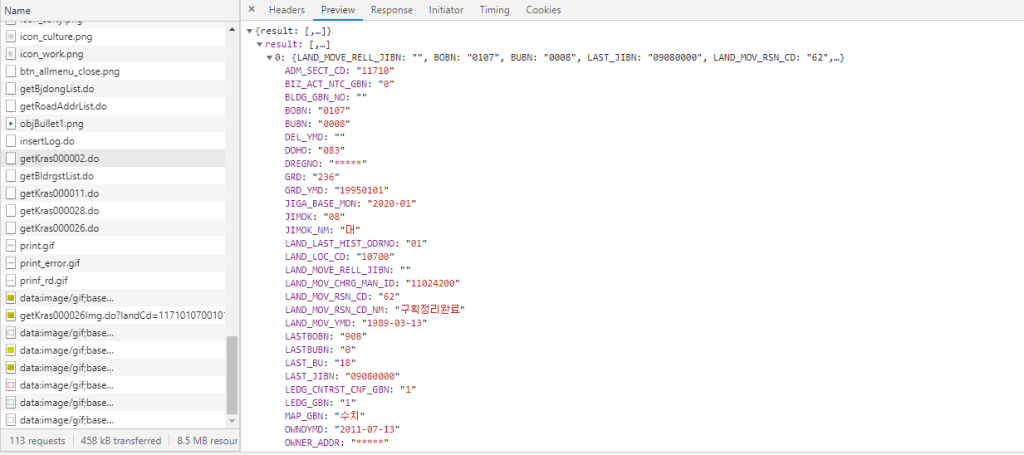

from selenium import webdriver
from bs4 import BeautifulSoup
import time
import requests
import json
browser = webdriver.Chrome()
browser.get('http://land.seoul.go.kr/land/wskras/generalInfo.do')
time.sleep(1)
browser.find_element_by_xpath('//*[@id="selSgg"]/option[text()="송파구"]').click()
time.sleep(1)
browser.find_element_by_xpath('//*[@id="selBjdong"]/option[text()="가락동"]').click()
time.sleep(1)
browser.find_element_by_xpath('//*[@id="bonbeon"]').send_keys("111")
time.sleep(1)
browser.find_element_by_xpath('//*[@id="btnSearch"]').click()
time.sleep(1)
browser.find_element_by_xpath('//*[@id="btnSearch"]').click()
custom_header = {
'referer' : 'http://land.seoul.go.kr/land/wskras/generalInfo.do',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
url = "http://land.seoul.go.kr/land/wskras/getKras000002.do"
req = requests.get(url, headers = custom_header).text
stock_data = json.loads(req)
print(stock_data)
-
-
(•́ ✖ •̀)
알 수 없는 사용자 - 〉

댓글 입력