셀레니움 및 뷰티플 수프 이용한 크롤링 질문입니다.
조회수 689회
안녕하세요 파이썬을 이용해서 자동로그인 및 크롤링 연습중인 초보 입니다.
특정 사이트에 자동로그인 하여 원하는 정보를 크롤링 하려고 하는데 막혀버렸네요.
일단 셀레니움을 통해 자동로그인은 했습니다.
문제는 다음과 같습니다.
- 해당 사이트의 개발자도구를 통해 원하는 정보의 소스를 확인했는데 공부한것중에 안나오네요.
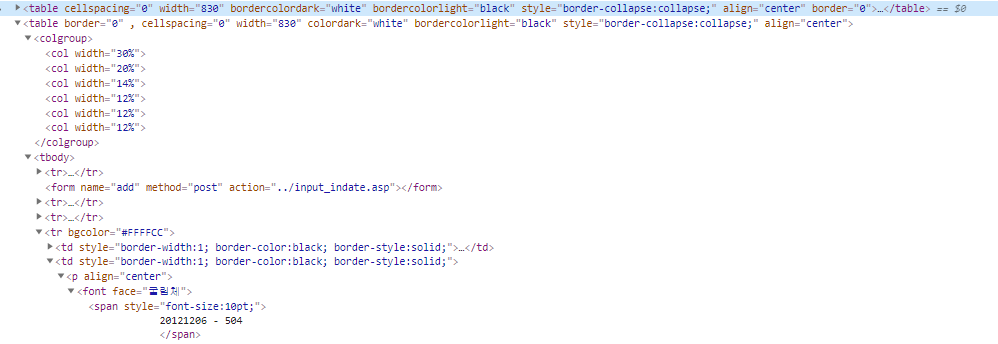
제가 원하는 정보는 하단에 나와있는 20121206-504

두번째 이미지에서 20121206-504 소스를 보면 위의 첫번째 이미지와 같습니다.
뷰티플 수프로 구현 시 소스를 어떤걸 사용하면 될까요? 구현 코드는 아래와 같습니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from time import sleep
from selenium.webdriver.support.ui import Select
from bs4 import BeautifulSoup
driver = webdriver.Chrome() driver.get("https://주소")
sleep(1)
driver.find_element_by_name('regi_no').send_keys('아이디')
driver.find_element_by_name('pass').send_keys('비밀번호')
driver.find_element_by_xpath('/html/body/div/form/center/input[1]').click()
sleep(3)
driver.find_element_by_xpath('//*[@id="myModal01"]/div/div/div[3]/button').click()
sleep(2)
driver.find_element_by_xpath('//*[@id="myModal02"]/div/div/div[3]/button').click()
sleep(2)
driver.find_element_by_xpath('//*[@id="myModal03"]/div/div/div[3]/button').click()
sleep(2)
driver.find_element_by_xpath('//*[@id="myModal04"]/div/div/div[3]/button').click()
sleep(2)
driver.find_element_by_name('grcode').click()
sleep(2)
driver.find_element_by_xpath('/html/body/table[3]/tbody/tr[3]/td[1]/p/font/span/select/option[2]').click()
-
-
(•́ ✖ •̀)
알 수 없는 사용자 - 〉

1 답변
-
웹드라이버를 통해 원하는 페이지에 방문했다면 해당 페이지의 소스를 받아와 BeautifulSoup으로 작업합니다.
html = driver.page_source soup = BeautifulSoup(html, 'html.parser)- 페이지 소스가 불명확해서요... 해당되는 태그가 뭔지 모르겠습니다. span이라고만 나오고 다른 class나 name가 없네요.. 알 수 없는 사용자 2021.3.2 19:51
- 정확한 해결을 위해서는 soup 출력물이 필요합니다만.. 개발자 도구를 봤을 때, 셀렉터를 font > span으로 지정해주면 될 것 같습니다. 초보자 2021.3.3 10:37

댓글 입력