
1 답변
-
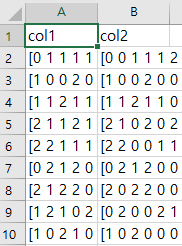
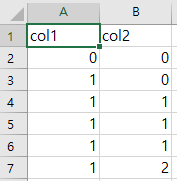
- 기본 라이브러리만 사용
import csv from collections import defaultdict import itertools as it with open('input.csv', 'r') as rf, open('output.csv', 'w') as wf: csv_reader = csv.DictReader(rf, delimiter=',') result = defaultdict(list) for row in [{key:value[1:-1].split()} for line in csv_reader for key, value in line.items()]: for key, value in row.items(): result[key].extend(value) csv_writer = csv.writer(wf) csv_writer.writerow(result.keys()) csv_writer.writerows(it.zip_longest(*result.values()))- 3rd 라이브러리 사용
import pandas as pd import numpy as np df = pd.read_csv('input.csv', converters={'col1':lambda line:line[1:-1].split(), 'col2':lambda line:line[1:-1].split()}) pd.DataFrame.from_dict({'col1': np.concatenate(df['col1'].values), 'col2':np.concatenate(df['col2'].values)}, orient='index').transpose().to_csv('output.csv', index=False)

댓글 입력