Python pytesseract 를 이용한 OCR 성능 문제
조회수 598회
안녕하세요
PDF 파일에서 글자를 추출하고자 합니다. 기존에 pdftotext를 사용하니 글자는 잘 추출하지만 이미지 처리된 글자의 경우 가져오지 못해서 아예 pdf 파일 전체를 OCR로 글자를 추출해보려고 합니다.
인터넷에 있는 코드를 따라 아래와 같이 실행해보았습니다.
# Import libraries
from PIL import Image
import pytesseract
import sys
from pdf2image import convert_from_path
import os
# Path of the pdf
PDF_file = "/Downloads/파일.pdf"
pages = convert_from_path(PDF_file, 500)
image_counter = 1
for page in pages:
filename = "page_"+str(image_counter)+".jpg"
page.save(filename, 'JPEG')
image_counter = image_counter + 1
filelimit = image_counter-1
outfile = "out_text.txt"
f = open(outfile, "a")
for i in range(1, filelimit + 1):
filename = "page_"+str(i)+".jpg"
text = str(((pytesseract.image_to_string(Image.open(filename), lang='kor'))))
text = text.replace('-\n', '')
f.write(text)
f.close()
결과의 일부입니다.
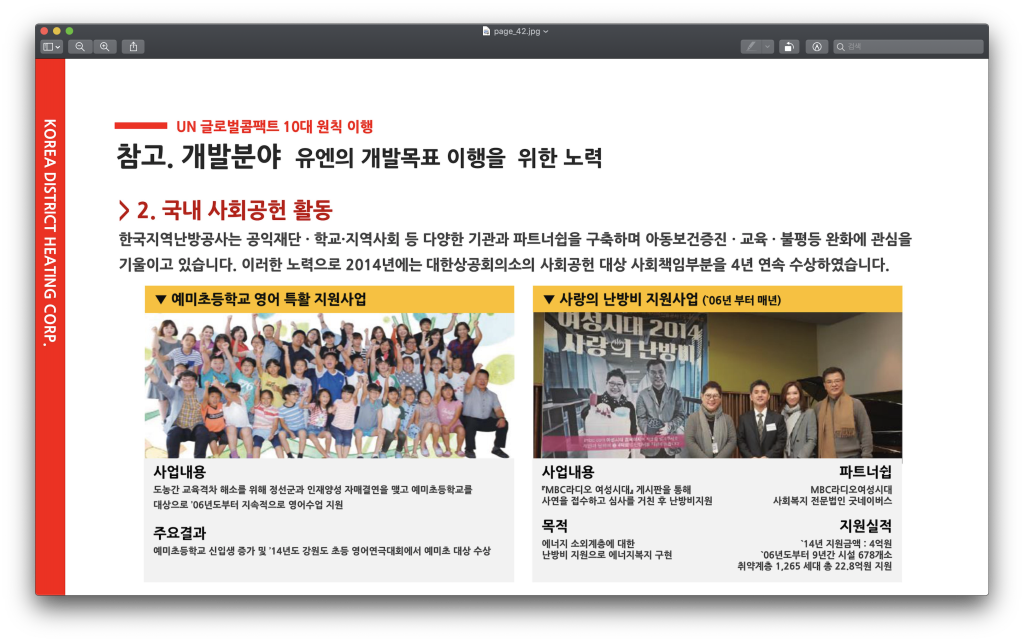
원본 pdf 파일의 이미지입니다.
보시는 바와 같이 글자를 제대로 인식못하고 띄어쓰기가 없는데도 모든 글자에 띄어쓰기가 되어 나옵니다.
pdf 파일 문제라고 하기엔 다른 파일 5개에도 같은 결과가 나오는데 해결방법이 있을까요?
감사합니다.
-
(•́ ✖ •̀)
알 수 없는 사용자
댓글 입력