Python pandas dataframe 에서 json_normalize와 apply를 대체할 수 있는 방안이 있을까요?
조회수 681회
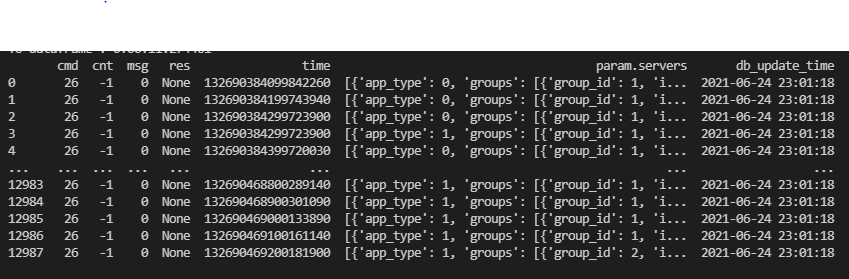
# json 파일 읽은 후 pandas dataframe으로 만들기
items = [ pd.read_json('somepath', lines=True, chunksize=100) ]
df = pd.concat(items, ignore_index=True)
# param.servers 컬럼의 json 구조에서 groups 키와 items 키를 각각 펼친 후 같은 index끼리 합치기
df_servers = pd.json_normalize(df['param.servers'].explode('param.servers')).explode('groups').reset_index()
df_groups = pd.json_normalize(df_servers['groups']).drop(['status'], axis=1)
df_items = pd.concat([df_servers, df_groups], axis=1).explode('items').drop(['groups'], axis=1).reset_index()
df_ = pd.concat([df_items, pd.json_normalize(df_items['items'])], axis=1)
질문 1) 파일 용량은 100MB 정도 됩니다 원본 row는 12987개이고 param.servers를 각각 explode 이후 json_normalize하여 펼치면 row 수가 30만개가 넘어갑니다. 이 과정에서 20초 이상 걸리더군요... Spark만큼은 아니더라도 이미지에 보이는 param.servers 컬럼과 같은 구조를 flat하게 만드는 과정에서 속도를 줄일 수 있는 방법이 있을까요? json_normalize 외에 벡터라이즈로 연산이 가능할까요?
질문 2)
df_['item_time'] = pd.to_datetime(df_['item_time']/10000000 - 11644473600, unit='s').astype('datetime64[s]')
time 컬럼을 datetime으로 만들기 위해 해당 문장으로 구현했습니다. datetime을 만들 때 더 좋은 함수가 있을까요?
★질문 3)
df_['item_param'] = df_.apply(lambda x : 'null' if 'null' in x['item_param'] else list(json.loads(x['item_param']).values())[0], axis=1)
json_normalize를 통해 펼치면 item_param이란 컬럼이 나옵니다. 해당 컬럼의 값이 null이란 글자를 포함하고 있으면 null 문자열로 채우고 그렇지 않다면 json 구조로 만들어서 첫 번째 value 값으로 채웁니다. (axis는 1입니다.) 이 과정을 구현하기 위해서 apply 함수를 사용했는데 row수가 많아지면서 속도가 많이 떨어지네요.. 혹시 해당 과정을 구현할 수 있는 더 좋은 함수가 있을까요?

댓글 입력