파이썬 크롤링 관련하여 질문드립니다.
조회수 358회
//from xml.dom.minidom import Element
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import pyautogui
from bs4 import BeautifulSoup
url = pyautogui.prompt("URL을 입력하세요")
browser = webdriver.Chrome("C:/chromedriver.exe")
browser.implicitly_wait(10) #10초 기다리기
browser.maximize_window() #전체화면
browser.get(url)
#Selenium - BeatifulSoup 연동방법
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
infos = soup.select("div.root")
#최근 30일 필터
browser.find_element_by_link_text("영상").click()
time.sleep(2)
browser.find_element_by_tag_name("span.fold__icon").click()
time.sleep(2)
span_element= browser.find_elements_by_tag_name("span.txt")
span_element[27].click()
time.sleep(2)
#스크롤 전 높이
before_h = browser.execute_script("return window.scrollY")
#무한 스크롤(feat.반복문)
while True:
#맨 아래로 스크롤을 내린다.
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
# 스크롤 사이 페이지 로딩 시간
time.sleep(2)
#스크롤 후 높이
after_h =before_h = browser.execute_script("return window.scrollY")
if after_h == before_h :
break
before_h = after_h
for info in infos :
#구독자 수
fan_num = info.select_one("div.meta .num").text
views = info.select_one("span.count")
print(fan_num,views)
여기서 span.count 클래스를 맨 위 해당 url에서 확인하면 18이라는 숫자입니다. 근데 text를 붙여서 가져오려고하면 에러가 뜨고, text를 안붙이고 가져오면 None값을 가져옵니다.. 원하는 18이라는 숫자를 가져오고 싶은데 왜 이럴까요..
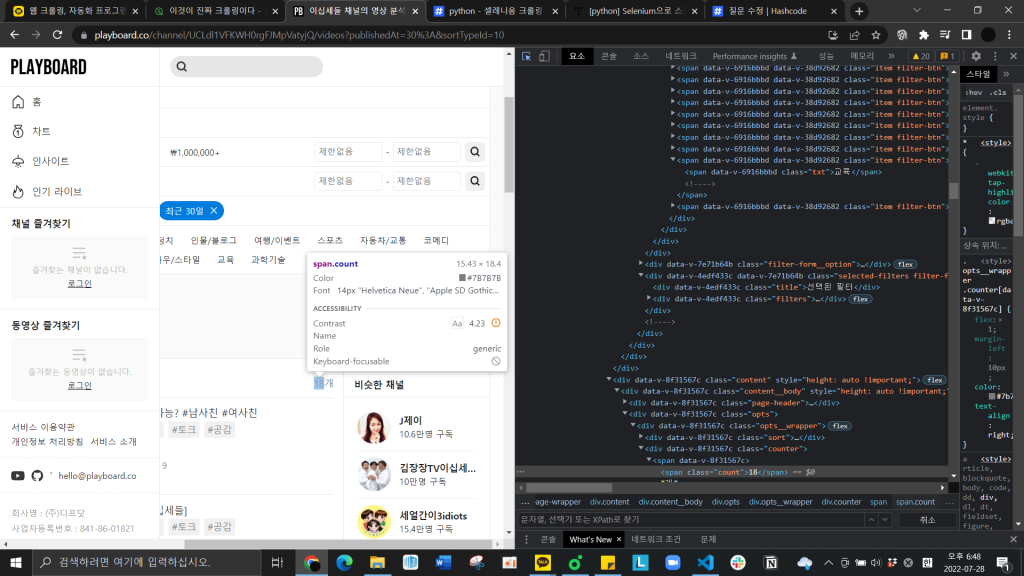 사진은 문제의 태그가 있는 작업관리자 화면입니다.
사진은 문제의 태그가 있는 작업관리자 화면입니다.

댓글 입력