다익스트라 알고리즘을 파이썬으로 구현한 예제 코드 분석하는데 질문드립니다. (도와주세요!!!)
조회수 3315회
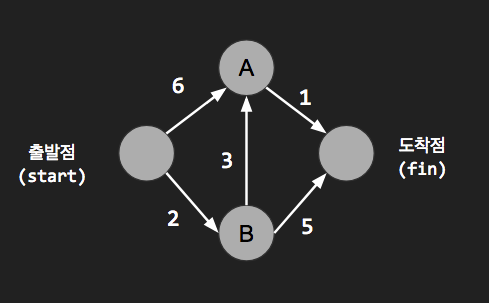
graph = {}
graph["start"] = {}
graph["start"]["a"] = 6
graph["start"]["b"] = 2
graph["a"] = {"fin": 1} # graph["a"]["fin"] = 1
graph["b"] = {"a": 3, "fin": 5} # graph["b"]["a"] = 3 graph["b"]["fin"] = 5
graph["fin"] = {}
# 노드의 가격을 저장하는 해시테이블
infinity = float("inf") # 파이썬에서 무한 표현 방법은 float('inf') 를 사용한다.
costs = {}
costs["a"] = 6
costs["b"] = 2
costs["fin"] = infinity
# 부모를 위한 해시테이블
parents = {}
parents["a"] = "start"
parents["b"] = "start"
parents["fin"] = None
processed = [] # 각 노드는 한번씩만 처리해야하므로 이미 처리한 노드를 기록해놓을 리스트가 필요하다.
# 가장 싼 노드를 찾는 함수
def find_lowest_cost_node(costs):
lowest_cost = float("inf")
lowest_cost_node = None
for node in costs: # 비용 테이블에서 노드를 하나씩 돌면서
cost = costs[node] # cost = {'a' : 6, 'b' : 2, fin : infinity}
if cost < lowest_cost and node not in processed: # 확인중인 노드의 비용이 최저 비용보다 낮고 그 노드가 처리되지 않은 노드일 때
lowest_cost = cost # 최저 비용 갱신
lowest_cost_node = node # 최저 비용 노드 갱신
return lowest_cost_node
node = find_lowest_cost_node(costs) # 아직 처리하지 않은 가장 싼 노드를 찾는다. # b
# 모든 노드를 처리하면 반복문 종료
while node is not None:
cost = costs[node] # cost = {'a' : 6, 'b' : 2, 'fin' : infinity} # 초기 cost = costs[b] = 2
neighbors = graph[node] # neighbors = {'a' : {'fin' : 1}, 'b' : {'a': 3, 'fin': 5}, 'fin' : {} }
for n in neighbors.keys(): # 모든 이웃에 대해 반복 [start][a] = 6 [start][b] = 2 [a][fin] = 1 [b][a] = 3 [b][fin] = 5
new_cost = cost + neighbors[n]
if costs[n] > new_cost: # 새 노드를 지나는 것이 가격이 더 싸다면
costs[n] = new_cost # 노드의 가격을 새 노드의 가격으로 갱신
parents[n] = node # 부모를 이 노드로 새로 설정
processed.append(node) # 노드를 처리한 사실을 기록
node = find_lowest_cost_node(costs) # 다음으로 처리할 노드를 찾아 반복
print('부모 테이블 (경로 이동) : ')
print(parents)
print('최단 거리 노드 비용은 : ')
print(costs)
# 출력결과
# 부모 테이블 (경로 이동) :
# {'a': 'b', 'b': 'start', 'fin': 'a'}
# 최단 거리 노드 비용은 :
# {'a': 5, 'b': 2, 'fin': 6}
다익스트라 알고리즘의 의미는 이해했습니다. 근데 이 알고리즘이 구현돼있는 코드를 분석하는데 어려움이 있어서요;; 실제 출력되는 결과랑 분석한 결과가 다르더군요 ㅠㅠ 왜 부모 테이블 (경로 이동)에 start가 포함되는지 모르겠습니다 ㅠㅠ
- find_lowest_cost_node(costs)함수 안의 for문(for node in costs)이 실행되는 순서를 처음부터 보면, node가 a -> b -> fin 순서대로 실행되나요? 다시 말해서, node = a -> cost = 6 -> lowest_cost = 6 -> lowest_cost_node = a node = b -> cost = 2 -> lowest_cost = 2 -> lowest_cost_node = b node = fin -> cost = infinity
따라서 처음에는 node = find_lowest_cost_node(costs) = 2 가 되는건가요?
- 1번 질문대로라면, while문에서 cost = costs[b] = 2 neighbors = graph[b] 가 되고,
for문을 실행되는 순서를 보면, n = a -> new_cost = 2 + 3 = 5 -> costsa > new_cost -> costs[a] = 5 -> parents[a] = b n = fin -> new_cost = 2 + 5 = 7 -> costsfin > new_cost -> costs[fin] = 7 -> parents[fin] = b processed = [b] 가 되는건가요?

1 답변
-
parent는 최적 경로로 찾아갈 때 그 노드를 방문하기 이전 노드를 기록합니다. start에서 b로 향해 이동했으므로 b의 parent는 start가 됩니다. 경로를 출력할 때는 end에서 시작해 스택에 쌓은 뒤 출력할 수 있습니다.
List item
처음에는 b라고 쓰여있습니다.
b -> a -> fin 순으로 방문하고 fin은 7의 cost를 가진 적이 없습니다.
- a : 6, b :2, fin : infinity
- a : 5, b :2, fin : infinity
- a : 5, b :2, fin : 6
-
(•́ ✖ •̀)
알 수 없는 사용자
댓글 입력