파이썬 웹크롤링 중 웹페이지 파싱 관련 질문입니다.
조회수 1248회
import requests
response = requests.get('http://?????/')
html = response.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.select('tbody'):
print(tag.text)
주소는 사내용이기에 지웠습니다.
프린트 하는 내용에서 tbody속 전체 태그중에 strong이라는 태그와 lmis 태그 두 종류만 출력하고 싶습니다.
각각을 출력하면 strong이 전부 출력되고 후에 lmis가 전부 출력되는 형태에서 막혔습니다.
strong / lmis 이런식으로 출력 가능하게 만들고 싶고 lmis가 숫자형식인데
1000이상인 경우만 도출되게 만들고 싶습니다ㅠ
도움을 주세요
-
-
(•́ ✖ •̀)
알 수 없는 사용자 - 〉

3 답변
-
사내망은 아니고 저희가 사용하는 장비를 모니터링하기 위해 제작한 사이트입니다.
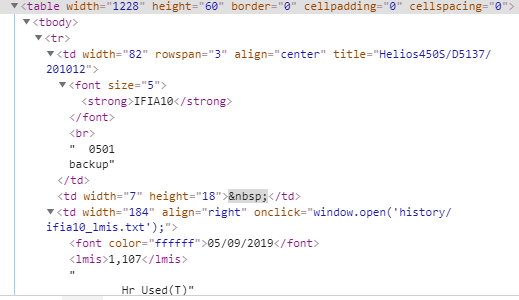
파이썬 초보라서 설명을 잘 못한거 같습니다.
IFIA10 1,107 이 두가지를 도출하고 싶습니다. lmis는 시간을 나타내는거라서 1000시간 이상인것들만 출력되게 만들고자 합니다.
-
(•́ ✖ •̀)
알 수 없는 사용자
-
-
print(tag.tr.td.font.strong.text) print(tag.tr.td.lmis.text)콤마를 지우고 int로 바꾸고싶다면,
a = tag.tr.td.lmis.text print(int(a.text.replace(',' , '')))1000 이상만 출력하고싶다면,
a = tag.tr.td.lmis.text a = int(a.replace(',' , '')) if a>=1000: print(a)- 제가 작성한 코드에서 print부분을 작성해주신 내용으로 바꿧더니 AttributeError : 'NoneType" object has no attribute 'td' 라고 뜨거든요 어떤게 잘못인지 알 수 있을까요? 알 수 없는 사용자 2019.5.20 03:03
-
td를 못잡는것같네요 select를 쓴 이유가 따로 있나요??
print(soup.find('strong').text) print(soup.find('lmis').text)for tag~~ 구문 지우고 이거한번 해보실래요

댓글 입력