파이썬 웹크롤링 질문 있씁니다.
조회수 603회
import requests
response = requests.get('http://?????/')
html = response.text
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') for tag in soup.select('tbody'): print(tag.text) 주소는 사내용이기에 지웠습니다.
프린트 하는 내용에서 tbody속 전체 태그중에 strong이라는 태그와 lmis 태그 두 종류만 출력하고 싶습니다. 각각을 출력하면 strong이 전부 출력되고 후에 lmis가 전부 출력되는 형태에서 막혔습니다. strong / lmis 이런식으로 출력 가능하게 만들고 싶고 lmis가 숫자형식인데 1000이상인 경우만 도출되게 만들고 싶습니다ㅠ 도움을 주세요
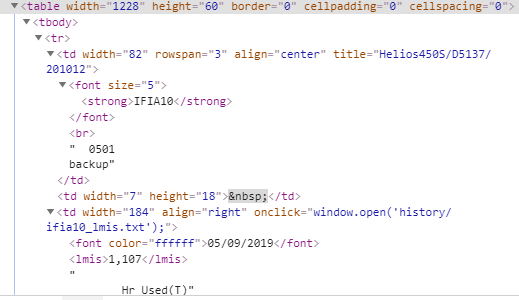
해당 소스에서 IFIA10 1,107 두가지를 출력해내고 싶고 1107이라는 숫자는 시간을 나타내는것입니다. 1000시간 이상인 경우만 출력하고 싶습니다.
-
(•́ ✖ •̀)
알 수 없는 사용자
1 답변
-
맞는지 확인 못했으니 참고만 하세요..
strong_tags = soup.tbody.findAll('strong') lmis_tags = soup.tbody.findAll('lims') for i in lmis_tags: if int(i.get_text().replace(',','') < 1000:lmis_tags.remove(i)위의 for문 대신 필터함수로도 가능할듯
lmis_tags = list(filter(lambda i: int(i.get_text().replace(',','')) >= 1000,lmis_tags))-
(•́ ✖ •̀)
알 수 없는 사용자
- 안녕하세요 답변 감사합니다. 제가 작성한 코드에 print(tag.text) 를 지우고 이었는데 진행이 안됩니다. 혹 제가 작성한 코드에 잘못된 부분이 있나요? 알 수 없는 사용자 2019.5.14 22:32
- 그 위에 for문도 필요없을듯... 위에 참고로 답변드린 코드는 그냥 생각나는 대로 적은 것입니다. 저도 파이썬 초딩입니다. ㅠㅠ 구체적으로 무슨 에러인지 알아야.... 확실한 설명이 필요하시면 구체적인 코드를 통해 고수님께 조언을.. 알 수 없는 사용자 2019.5.14 22:50
-
댓글 입력