BeautifulSoup로 웹 크롤링 할 때 모든 html 코드가 다운되지 않는 현상이 발생합니다
조회수 838회
ebsi 에서 기출문제를 자동으로 다운 받을 수 있는 코드를 python으로 짜던 중 beautifulsoup로 웹 페이지를 다운 받아보니 사이트의 html코드보다 축약된 코드가 다운 받아졌습니다.
BeautifulSoup로 웹 크롤링 할 때 모든 html 코드가 다운되지 않는 현상이 발생합니다.
import requests
from bs4 import BeautifulSoup as bs
login_info = {
'userid': '00000000',
'passwd': '00000000'
}
with requests.session() as s:
login_req = s.post('https://www.ebsi.co.kr/ebs/pot/potl/SSOLoginSubmit.ebs', data = login_info)
print(login_req.status_code)
page_req = s.get('http://www.ebsi.co.kr/ebs/xip/xipc/previousPaperList.ebs')
html = page_req.text
soup = bs(html, 'html.parser')
이렇게 코드를 짜서 나온 soup 값을 보니까
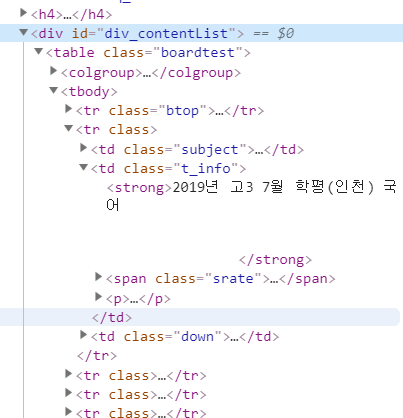
이렇게 나와야 하는 부분이
(생략)
</select>
</span>
</em>
</h4>
<div id="div_contentList"></div>
</div>
</div>
</form>
</div>
(생략)
이렇게 나와 버립니다.
(전체 결과를 올리기엔 5000줄이나 되서 이렇게 캡처로 올렸습니다.)
어떻게 하면 이렇게 짤려서 나오는 현상을 해결할 수 있을까요?

1 답변
-
아마 클라이언트 단의 스크립트가 페이지를 추가로 렌더 할 가능성이 있을 것 같습니다.
이럴 경우에는 단순히 HTML 크롤링이 아니라 셀레니움을 이용해 브라우저로 렌더해서 크롤링 해야 할 것 같습니다.
-
(•́ ✖ •̀)
알 수 없는 사용자
-
댓글 입력