python requests로 데이터 가져올 때 403 forbidden이 나타나는 문제 질문드립니다
조회수 3853회
우선 스크랩/파싱하고자 하는 페이지는 다음과 같습니다.
일반적으로 requests를 사용하듯 페이지에 접근했는데, 계속 403 forbidden 에러를 내려줍니다. 관련되어 사용하고 있는 모든 헤더를 다 수정하여 추가했는데도 마찬가지로 나타납니다.
혹시 쿠키값이 필요한가 하여 쿠키값을 제거한 상태에서 requests.get()을 보냈는데, 브라우저로 네트워크를 살펴보니 쿠키값이 없는 상태로 보내진 최초 HTTP 통신에 값이 내려오는 것을 보니 쿠키값으로 유효성을 검증하는 것은 아닌 것 같았습니다.
이런 경우는 처음이라 혹시 고수분들의 고견을 들어볼 수 있을까 하여 질문드립니다.
네트워크로 살펴보았을 때 서버 측에서 받는 requests header는 아래와 같았습니다.

해당 HTTP 미리보기를 보면 아래와 같이 브라우저에서 정상적으로 데이터를 받아온 것을 확인할 수 있었구요.
(waterfall로 보면 이게 최초의 HTTP 통신입니다)

POSTMAN을 통해 위의 requests header와 주소를 넣었을 때의 입력값입니다. 보시는 것처럼 403 Forbidden으로 튕겨내어지고 있습니다.
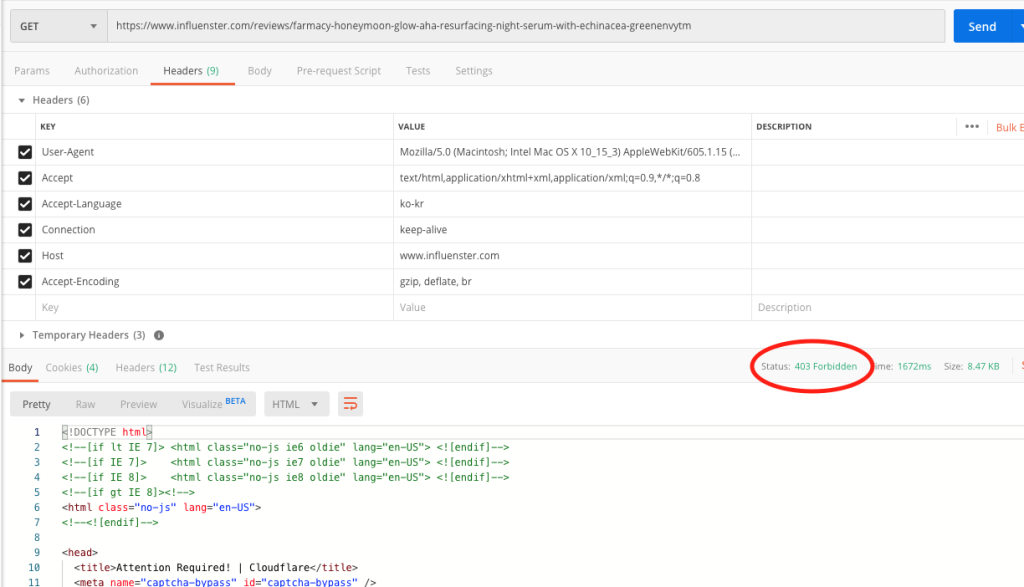
쿠키값이 복잡하게 설정되어있다든가, csrf나 JWT가 필요하다거나 하면 어떻게든 뚫어볼텐데, 딱히 요구하는 커스텀 헤더도 없고, 서버에서 받는 요청 헤더를 다 맞추어 주었는데도 이렇게 튕겨내지는 경우는 처음이라 당황스럽습니다.
세션이 필요한가 하여 requests로 세션을 열고 보냈는데도 마찬가지입니다.
혹시 이 문제 해결 가능한 고수님이 계신지 기다려봅니다 ㅠㅠ
---- 사용된 헤더 ---
my_headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15',
'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : '[{"key":"Accept-Language","value":"ko-kr","description":"","type":"text","enabled":true}]',
'Connection' : 'keep-alive',
'Host' : 'www.influenster.com',
'Accept-Encoding' : 'gzip, deflate, br'
}
-
(•́ ✖ •̀)
알 수 없는 사용자
1 답변
-
이미 솔루션이 있네요.
pip install cfscrapeimport cfscrape scraper = cfscrape.create_scraper() r = scraper.get("https://www.influenster.com/reviews/farmacy-honeymoon-glow-aha-resurfacing-night-serum-with-echinacea-greenenvytm") r.status_code # 200 print(r.content.decode('utf-8'))- 감사합니다. 시도해보겠습니다! 알 수 없는 사용자 2020.2.4 19:41
- 시도해보았으나 cfscraper로는 작동이 안되고(똑같은 403 forbidden), 대신 찾아보니 cloudscraper라는 다른 모듈이 있는데 이건 작동하는 것 같습니다. 이 글을 보는 다른 분들을 위해 쓰자면, 사용법은 영훈님이 쓰신 것과 동일하게 import scraper하신 다음 scraper = cloudscraper.create_scraper()로 객체 만들어 사용하시면 됩니다. 감사합니다! 알 수 없는 사용자 2020.2.5 14:31
- 저는 잘 되었구요. 아마도 프로젝트에도 설명이 있는데 cloudflare 의 방법이 수시로 변경된다(당연하겠죠 뚫리면 막아야하니까요)고 되어 있구요 reCAPTCHA 가 나타나면 운이 없는거라고 나와 있어요. 이말은...항상 된다는 보장은 못하고 또 지금은 되어도 나중에 안될수 있다는 의미입니다. 막으려는 솔루션인데 뚫리면 존재이유가 없겠죠. 정영훈 2020.2.5 17:59

댓글 입력